Hostile DNS Management
One of the most annoying parts of modern technology is the invasive advertising that companies feel we are obliged to suffer. More than this, a significant portion of this advertising can contain malicious payloads that the ad host rarely seems interested in preventing. It’s time to take back the home network by blocking malvertising completely from all devices.
I’m going to say this first…. you can probably do most of this via a PiHole installation, however I’m not sure how many layers that covers. I recommend it for anyone having issues with their ISP or needing to keep their home browsing malvertising free. I’ve covered the topic lightly in a previous post on TikTok, but then I’ve had a few people ask how I’ve deployed it.
Aims & Objectives
We have two hats to wear here: the poacher trying to deploy surveillance, and the home user wanting to rid their network of hostile sites, advertising and create a safety net. I’m going to focus on the latter – if you want to understand how to defeat the latter this is a useful exercise in looking for clues.
You’ll get some fringe benefits too – caching DNS responses centrally means all devices will reduce the respnse times of web pages and apps repeatedly calling specific hosts.
While blocking malvertising I’ve discovered a few false positives – especially in dealing with network scanning apps (Chrome) and devices (iOS particularly) problematic – IDPS has repeatedly blocked iOS devices for attempted port scans and multi-protocol request groups so I’ve reduced the paranoia on the IDPS in very specific scenarios. I remain unsure why these devices need to do this although you should familiarise yourself with WebRTC to ensure protection is at appropriate level to enable feature, and no more.
This approach won’t really work fully with only a single node change… a combination is needed – router-level and DNS level. It didn’t feel right to co-locate DNS and router in our setup here, and I’m not particularly impressed with router firmware (even Asus Merlin) enough to do both. Whilst Asus properly responded to a vulnerability report I submitted I still see too many issues – particularly with packet fragmentation. I honestly don’t understand why router manufacturers insist on using old firmware with ancient Linux kernels, instead of well known distros on modern Linux kernels (arm64 or armel or armhf anyone? Come on! It’s 2022!).
I’ve used Asus as their hardware specs are better – running OpenVPN means you’re CPU-locked on tunnel bandwidth without being able to take advantage of more than one core.
Nevertheless, my overview diagram for blocking malvertising highlights the combination of router redirecting all DNS traffic to our LAN DNS server; the corresponding web requests for forbidden malvertising fruit sent to a web responder (which simply returns an empty pixel GIF); and the router allowing only our DNS server to make whatever requests it wants.
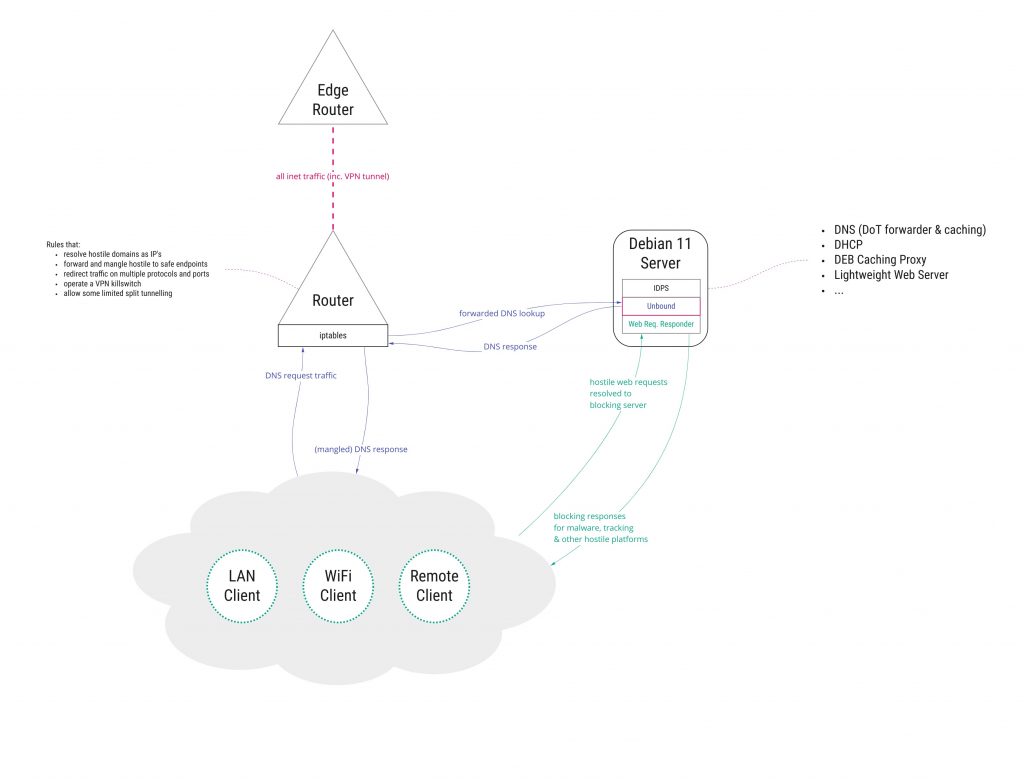
DHCP Server
Whether you’re using the router-based DHCP serving capabilities, or a decent dedicated DHCP service like ISC’s DHCP on Debian, you’ll need to configure the server to become authorative, and provide the IP of your DNS server as the primary and secondary server for all devices.
This is just the first step, as there will be apps and web sites that will ignore this setting (trying to use their own DNS services for example). However this step will ensure that all your devices are given a default setting, covering the majority of the scenarios.
If you’re applying sticky IPs to specific devices also ensure those groups are also given the same DNS server.
DNS Server
First up, we need to deploy a DNS capability to the network which will be used by all network devices.
In our friendly anti-malvertising scenario we can simply create a Debian 11 server (I’ve used the arm64 image and a RPi 4), deploying Unbound as the resolver. It’s fast, recursive and validating with the ability to call and verify DNS-over-TLS upstreams.
Warning: Unfortunately there’s an issue with 1.9.0-2+deb10u2 on Debian 10 if you’re using a chroot-ed config. SEGFAULT and crash on first query. I’ve masked to hold back to release 1.13.1-1 but I’ll be upgrading the server to Debian 11 soon.
If we were deploying a hostile DNS capability to conduct surveillance I would use a different approach likely involving a covertly installed or compromised device – I’m not going to discuss that here for what will hopefully be obvious reasons.
Other than standard DNS definitions there isn’t really a lot to do in basic config, the complexity is in acquiring hostile DNS entries from managed lists. You have a plethora of choices out there and here is one example specifically for unbound. It’s from pgl.yoyo.org – frankly whomever operates this deserves a medal.
You’ll need to script a regular download and incorporation into your Unbound config, along with a reload of the Unbound config via unbound-control. Something like:
# use the encrypted usb for temp storage to reduce wear on SD card
tempCache="/usb/location/unbound.cache"
# grab a copy of the response cache
unbound-control dump_cache > $tempCache
#### DO THE PULL AND SAVE RESULTS TO UNBOUND CONFIG HERE
# now the configuration is updated reload unbound
# (ditches the dns cache and updates with new configation of downloaded rules)
unbound-control reload
# .. if it errors often on reload, use a restart service instead
# systemctl restart unbound
# restore the pre-update response cache - the conf will override the cache if a domain becomes hostile
cat $tempCache | unbound-control load_cache
# scrub the cache file
rm $tempCache
For each source of malvertising domains you want to trust – and that is your choice – simply insert that pull request into the above algorithm.
You’ll also need to deploy either your choice of web server to serve a 1px by 1px transparent GIF file for every request… or use the delightful pixelserv. I haven’t had a chance to check it out yet, but I’m aware of a Diversion project called pixelserv-tls. Sounds promising in one sense however the responding server still won’t match the requesting domain so most clients will detect a certificate mismatch regardless. Really isn’t an issue in most instances.
In practise putting a friendly single web page up which is served instead of an advert or hostile site can appease users frustrations about the who-what-why… maybe they can raise it with you and you can have a positive conversation about why you blocked it in the first place.
Router Netfilter Approach
After we have an operational DNS capability on the target network, we need to enforce the use of it by silently pushing all DNS traffic towards our controlled / safe zone. If we were the poacher trying to deploy surveillance we’d also want to redirect without having to compromise all client devices on the network.
We’d collate a list of known hostile DNS providers and platforms who have their own DNS capabilities e.g. Faceflaps, Google, Comodo and Discord (there are many more). Special focus on CloudFlare as they’ve partnered with Faceflaps. The DNS-over-TLS ITEF working group was called “DPRIVE” for a reason…
I’ve created a script that does a DNS lookup (preferably use Idns drill, but Bind’s dig is fine) for each, collects the associated nameservers for each hostile domain and then adds them to a list. Each one can then be resolved to an IP address.
You’ll want to add common DNS servers like Cloudflare and Google into this list so that anyone using drill on your network gets the response you want, for example:
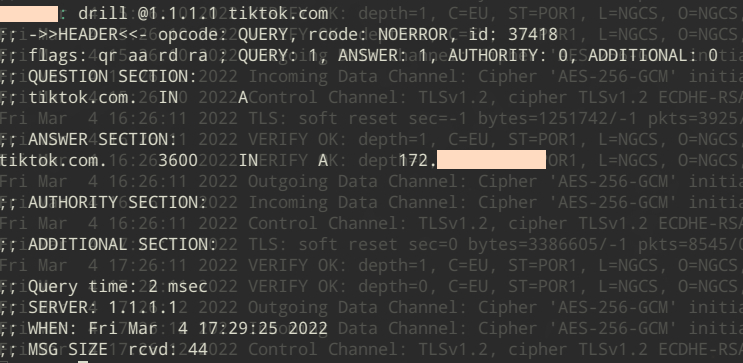
In the screenie above you can see an attempt to use an alternative DNS to get a true IP resolution for tiktik.com…. thwarted by our netfilter rules and being provided our LAN DNS IP instead.
You’ll need to take that final list of IP’s and loop through applying some pre- and post-routing rules on the router, which also apply a masquerade to the responses (to make the client think the responses came back from the server they requested it from). You can largely assume that DNS traffic is sent on 53, 5353, 853, 443 and 8443 but you may want to run some package capture to check against each hostile source.
So, for the generic ports you’d have something like the following in your router firewall startup script:
targetLanDNS=<your shiny new LAN DNS IP>
dnsPorts=<list of dns ports you want to focus on>
for port in $dnsPorts; do
# basic re-route on the request
iptables -t nat -A PREROUTING ! -s $targetLanDns -p tcp --dport $port -j DNAT --to $targetLanDns:$port
# masquerade the response
iptables -t nat -I POSTROUTING ! -s $targetLanDns -p tcp --dport $port -d $targetLanDns -j MASQUERADE
doneAnd then follow that up with similar rules that focus on known hostile DNS & DoT servers (irrelevant of the ports they may try and use) like so:
# where $dnsAddress is the item in your hostile DNS IP list
iptables -t nat -A PREROUTING ! -s $targetLanDns -p tcp --dport $port -d $dnsAddress -j DNAT --to $targetLanDns:853
# .... and ....
iptables -t nat -I POSTROUTING ! -s $targetLanDns -p tcp --dport $port -d $targetLanDns -j MASQUERADEDon’t forget: The DoT requests will likely fail at the client end due to a mismatch on the server certificate. Your aim here isn’t to dupe them but force them to fallback to plain DNS.
You’ll that these rules add an exception into these scripts so that the router allows your designated safe LAN DNS to make it’s forwarding requests.
You’ll have the usual challenges where the router firmware / OS is likely running an out-of-date kernel, plus it may require you to take additional steps to enable a package manager then finally allow you to install packages like idns and so forth to get at usable commands.
Asus Merlin is pretty good, DD-WRT is was ok but it looks like OpenWRT is taking the lead again. All three allow use of package managers (use a USB stick and JFFS).
If I were an attacked I might also try and compromise the router so ensure you schedule reboots regularly, and pipe all router logs to a centralised SIEM capability. Asus allows IP and port specification for rsyslog targets … defect fixed after I something I reported 😉
Additional Considerations
If we wanted to prevent our ISP trying to do almost exactly the same thing we’re doing (a number of US-based residential ISPs do this, one or two UK ISPs have also tried it); we’d put a secure tunnel into place to a ‘safer’ country. We could then direct all DoT traffic to a safe zone away from our hostile ISP.
This way the ISP has no connection records or meta-data for the queries we’re sending – which they’d be able to acquire even if they can’t see the content of the queries protected by DoT. Ideally we could funnel our web traffic too, so that they would be unable to collect connection records for that type of traffic.
There’s levels of complexity in this approach I found an interesting intellectual challenge, rather than a security necessity. You will have to choose your own level of involvement based on what you can commit to maintenance of your chosen solution.